专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2
在光学字符识别(OCR)领域,印刷体文字的识别已趋于成熟,但手写文字识别(Handwritten Text Recognition, HTR)因其书写风格的多样性、笔画的连笔与粘连、以及版面布局的非结构化特征,长期以来被视为计算机视觉与自然语言处理交叉领域的“硬骨头”。中科逸视(北京)科技有限公司针对这一难题,构建了一套融合图像处理、深度学习与自然语言处理(NLP)的多模态技术架构。该技术不再局限于传统的像素级字符分类,而是转向了对文档内容的语义理解与结构化重构。

技术架构原理:从“感知”到“认知”的跨越
中科逸视的手写文字识别系统并非单一模型的堆砌,而是一个串联了底层视觉感知、中层序列建模与高层语义纠错的流水线系统。其核心逻辑在于解决手写体中普遍存在的“形变”与“语境依赖”问题。
1. 图像预处理与增强(Image Processing)
手写档案往往伴随纸张泛黄、墨迹褪色、背景噪声甚至折痕干扰。传统的二值化方法容易丢失笔画细节或引入噪点。手写文字识别技术基于深度学习的图像增强模块:
2. 深度特征提取与序列建模(Deep Learning)
这是手写文字识别引擎的核心部分,主要解决“写得好认,写得潦草难认”的问题。我们采用了典型的Encoder-Decoder架构,并进行了针对性优化:
3. 语义纠错与结构化抽取(NLP Integration)
单纯的视觉识别容易产生同音字错误或生造字,尤其是在字迹模糊时。手写文字识别技术的创新之处在于将NLP技术深度融入识别后处理环节,实现从“识别”到“理解”的闭环:
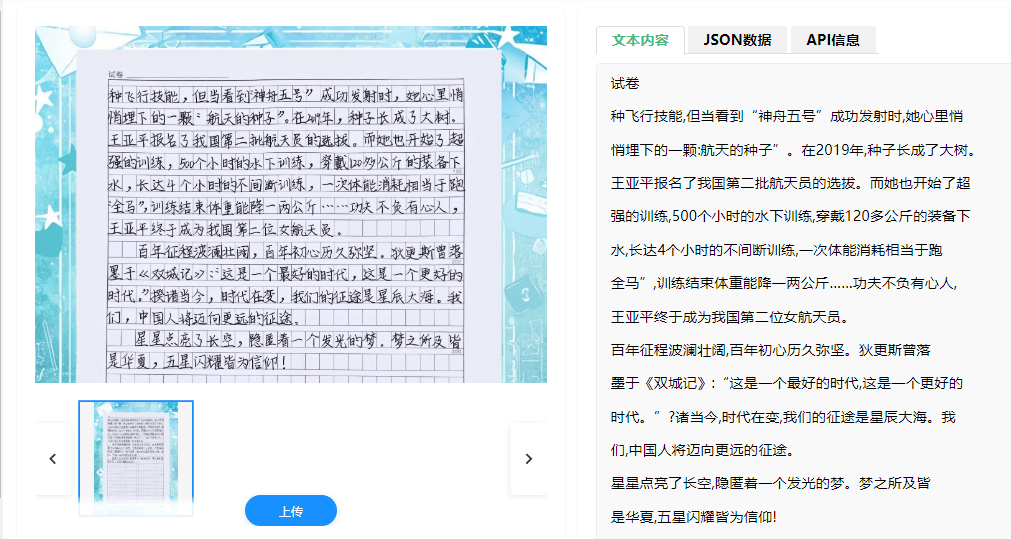
典型应用场景与技术挑战应对
手写文字识别技术体系已在多个场景中应用,解决了传统OCR无法处理的痛点。
1. 历史档案数字化与智慧知识库构建
场景特征:档案年代久远,纸张质量差,书写风格涵盖楷书、行书甚至草书,且存在大量异体字和繁体字。
技术应对:
2. 教育智能阅卷系统
场景特征:学生手写字迹稚嫩、潦草,涂改痕迹多,且主观题答案篇幅长、逻辑结构复杂。
技术应对:
3. 医疗与政务票据结构化
场景特征:医生处方、卫生许可证、手写登记表等,字段位置不固定,存在大量专业术语缩写和连笔。
技术应对:
中科逸视的手写文字识别技术,本质上是一场从“光学字符识别”向“智能文档理解”的范式转移。通过深度融合计算机视觉的感知能力与自然语言处理的认知能力,该技术成功突破了手写体非标准化带来的识别瓶颈。
其核心价值不在于单一的识别率提升,而在于构建了“图像增强 - 深度特征提取 - 语义纠错 - 结构化重组”的全链路解决方案。这种技术架构不仅适用于通用的文档数字化,更为历史档案挖掘、教育评估智能化、医疗政务数据治理等垂直领域提供了坚实的技术底座。未来,随着多模态大模型技术的进一步演进,该类技术在处理极度潦草字迹、跨语言混合书写以及复杂逻辑推理型文档理解方面,预计将展现出更强的泛化能力和智能化水平。