专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2
在企业的日常运营中,海量的非结构化文档——合同、订单、票据、法律文书、企业证照等承载着核心业务信息。然而,这些文档格式各异、布局多变,传统基于固定模板或规则引擎的OCR(光学字符识别)技术难以应对。近年来,OCR技术与大语言模型(Large Language Model, LLM)的深度结合,诞生了智能文档抽取系统。这类系统仅需用户上传少量样本并自定义配置抽取字段,即可自动将任意文档转化为结构化数据,极大提升了信息处理效率。本文将从核心原理、技术架构及应用场景三个维度,剖析文档抽取系统的内在机制。
背景与挑战
非结构化数据的困境
企业在日常运营中产生海量文档:
对于以上困境,传统OCR + 规则引擎泛化能力差,需为每种新文档编写正则/模板,维护困难。
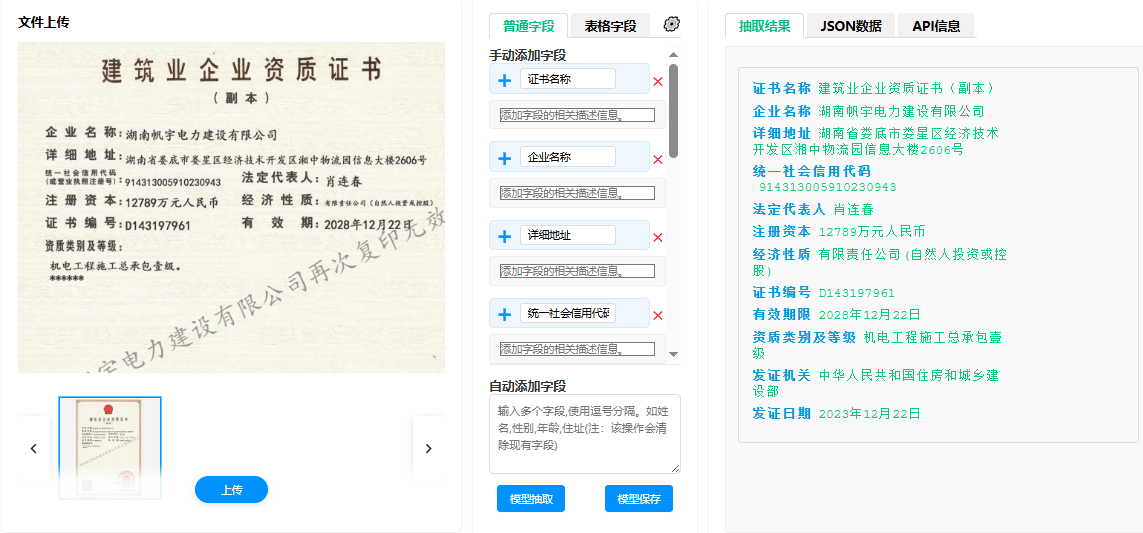
技术原理:OCR与大模型的协同进化
文档抽取系统采用“视觉感知(OCR)+ 语义理解(LLM)” 的双阶段混合架构,旨在兼顾精度与效率。
1.核心架构流程
第一阶段:高精度视觉预处理(OCR Layer)
利用高性能OCR引擎进行图像到文本的转换,并保留空间坐标信息。
第二阶段:大模型语义解析(LLM Layer)
将OCR输出的结构化文本块(含位置信息)作为Prompt输入给大语言模型。
第三阶段:后处理与验证
2.关键技术亮点
少样本学习(Few-Shot Learning)
位置感知的上下文窗口
自适应字段配置
应用场景
金融与保险
法律与合规
供应链与物流
政务与企业服务
基于OCR与大模型的文档抽取系统,融合了计算机视觉、自然语言处理与知识推理,打破了传统模板化抽取的桎梏。用户仅需上传少量样本并自定义字段,即可将堆积如山的非结构化文档转化为可计算、可分析的结构化数据。这一技术正在重塑合同审核、财务处理、法务管理等多个领域的工作模式,为企业释放出巨大的效率红利。