专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2
在信息爆炸的数字化时代,企业、政府机构和各类组织每天都要处理海量的非结构化文档——合同、票据、证照、报告、档案等。这些文档中蕴藏着巨大的数据价值,但传统依靠人工阅读、理解和录入的方式效率低下、成本高昂且容易出错。如何让机器不仅“看见”文档,更能“理解”文档,已成为制约众多行业数字化转型的关键瓶颈。中科逸视(北京)科技有限公司的智能文档抽取系统,正是为解决这一痛点而生。
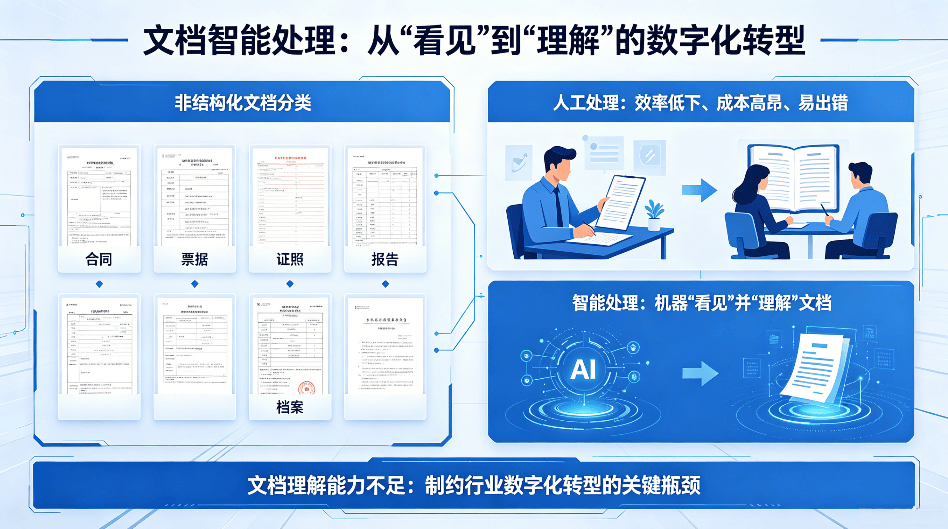
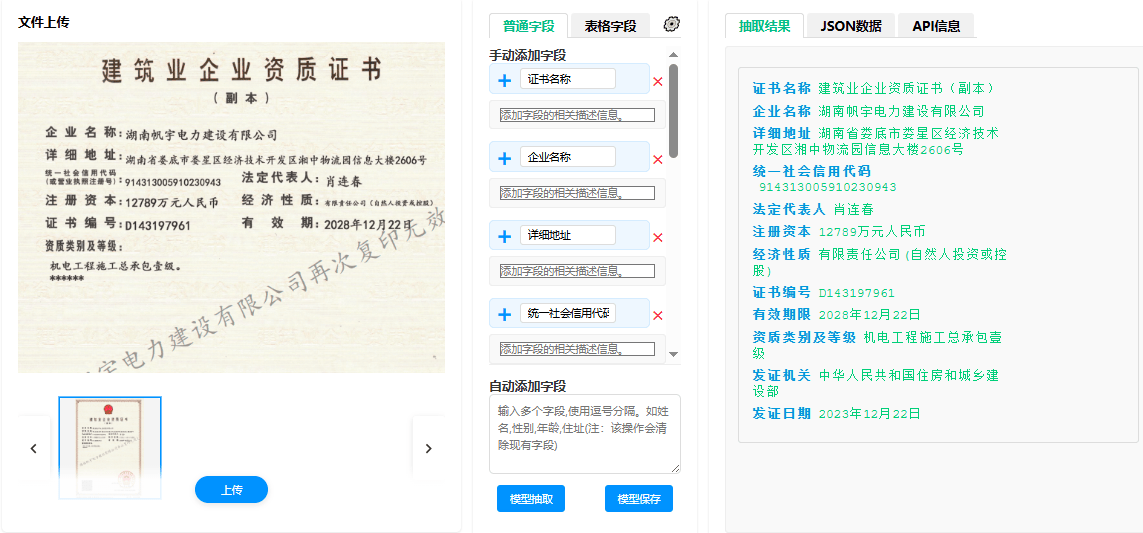
技术架构:大模型与高精度OCR的双轮驱动
中科逸视智能文档抽取系统的核心在于将前沿的大语言模型微调能力与自研的高精度光学字符识别引擎进行深度耦合,形成端到端的智能文档理解与结构化信息抽取平台。它不仅仅是在“阅读”文档,更是在“理解”文档——能够洞察文档的语义内涵与逻辑结构。这一技术体系可以拆解为两个相互衔接又深度融合的环节:
1. 高精度OCR引擎:构建专业的文档解析底座
OCR模块不仅输出纯文本,还保留空间布局与视觉语义线索(如坐标、字体、行高、段落关系等元信息),为后续大模型提供上下文感知的输入。
2. 大语言模型微调训练:注入语义理解能力
单纯OCR输出的文本是离散且缺乏结构关联的。中科逸视文档抽取系统引入大语言模型作为语义理解与信息抽取的核心引擎,并通过领域自适应微调使其适配各类业务场景。其关键技术包括:
3. 版式无关的通用抽取能力
传统基于规则或模板的方法难以应对文档版式的多样性。中科逸视的文档抽取技术通过“视觉-语义联合建模”,将文档的布局信息(如坐标、字体、段落层级)与文本语义深度融合输入大模型,实现对PDF、Word、扫描图像、网页截图等异构格式的统一处理,真正做到“一模型适配千种版式”。
应用领域:从核心金融到基层政务
金融与保险
法律与合规
供应链与物流
人力资源
中科逸视智能文档抽取系统以专业的文档解析底座和大模型智能语义理解能力为核心,成功地将视觉识别与语义理解深度融合,构建了一套能够理解文档语义、洞察逻辑结构的智能处理系统。其技术原理的科学性、泛化能力的优越性以及应用领域的广泛性,使其成为各行业文档智能化处理的有力引擎。