企业证照管理是组织运营中的基础性工作,涉及营业执照、资质证书、许可文件等多种类型文档的归档、核验与更新。传统管理方式多依赖人工录入与复核,存在效率瓶颈与差错风险。随着文档智能化处理技术的发展,基于大模型与光学字符识别(OCR)融合的文档抽取技术,为证照管理提供了新的技术路径。中科逸视(北京)科技有限公司在该领域进行了技术探索,本文将就其技术原理与应用实践进行阐述。

技术架构与原理
中科逸视的文档抽取技术建立在一个核心认知上:证照文档的处理不能仅依赖单一的OCR识别或通用的语言模型,而需要将两者的优势进行系统性融合。该技术体系主要由高精度OCR引擎与领域微调的大模型两部分构成,两者协同完成从图像到结构化信息的转换。
1.高精度OCR:构建文本基础
OCR技术承担着将证照图像转化为可编辑文本的基础功能。针对证照文档的特点,文档抽取系统在OCR环节进行了针对性优化:
-
图像预处理增强:针对证照拍摄中常见的光照不均、倾斜、折痕、印章遮挡等问题,系统集成了自适应二值化、透视校正、去噪增强等预处理算法,提升图像质量,为后续识别奠定基础。
-
版面分析与区域定位:证照文档具有固定的版面结构,但不同颁发机构、不同时期的证照在格式上存在差异。系统通过版面分析技术,自动识别文档中的字段区域、表格结构、印章位置等布局信息,而非进行全文本的简单转录。
-
关键区域识别:结合证照的先验知识(如营业执照中“统一社会信用代码”通常位于标题下方右侧),系统对关键字段区域进行优先识别与交叉验证,降低全文本识别的误差累积。
2.大模型微调训练:实现语义理解
单纯OCR输出的文本是离散且缺乏结构关联的。文档抽取系统引入大语言模型作为语义理解与信息抽取的核心引擎,并通过微调训练使其适配证照管理场景。
-
领域适配微调:基于通用基座大模型,使用包含营业执照、建筑业资质、安全生产许可证、ISO认证等多种类型证照的标注数据集进行有监督微调。训练数据涵盖不同版式、不同填写规范的真实样本,使模型学习到证照文档的特定语言模式、字段间的逻辑关系以及行业术语的准确含义。
-
关键字段定义与抽取:根据企业证照管理的实际需求,系统预定义了关键字段体系,包括但不限于:企业名称、统一社会信用代码、法定代表人、注册资本、成立日期、有效期、发证机关、资质等级、许可范围等。模型在推理时,并非简单地在文本中匹配关键词,而是基于对文档语义的整体理解,准确定位并抽取对应字段的取值。
-
多版式泛化能力:由于同一类证照在不同时期或不同地区可能存在版式差异,通用模板匹配方法难以覆盖所有情况。微调后的大模型通过语义理解而非位置规则进行抽取,对版式变化具有较好的泛化能力。例如,无论“有效期”字段位于证照左上角、右下角还是以表格形式呈现,模型均能根据语义特征进行识别。
3.融合机制:OCR与大模型的协同
OCR与大模型的融合并非简单的流水线串联,而是存在多层次的交互与校验:
-
OCR文本作为输入:OCR识别结果(包括文本内容、位置坐标、识别置信度)作为大模型的主要输入信息。
-
置信度传递与纠错:当OCR对某区域识别置信度较低时,系统将该信息传递至大模型,模型可结合上下文语义进行推测与纠错。例如,OCR将“有限责任公司”误识为“有限贡任公司”,大模型可依据常见公司类型表述进行修正。
-
多模态信息辅助:除文本外,证照中的印章、防伪标记、照片等视觉信息在某些场景下对字段验证具有辅助作用。系统在架构上保留了多模态信息接入的接口,为后续技术迭代提供基础。
在企业证照管理中的应用实现
证照入库与信息抽取
企业证照管理的起点是各类证照文档的归集。在实际应用中,用户通过扫描仪、高拍仪或移动设备采集证照图像,系统自动完成以下处理流程:
-
图像质量自动检测与预处理,对不合格图像实时提示重拍或校正;
-
OCR识别与版面分析,提取文档中的完整文本及布局信息;
-
大模型根据预定义的关键字段体系进行语义抽取,输出结构化的JSON数据;
-
抽取结果推送至企业管理系统,完成证照信息的自动化入库。
整个过程将原本需要数分钟的人工录入工作压缩至秒级完成,且减少了人工录入时的字段遗漏或誊抄错误。
有效期监控与预警
证照管理的一项核心任务是确保各类资质的持续有效。文档抽取系统在抽取证照信息时,将有效期、发证日期、年检要求等时间相关字段作为重点抽取对象。抽取后的信息进入企业管理系统后,可自动触发以下功能:
-
建立证照有效期台账,按证照类型、所属部门进行分类管理;
-
对临近到期的证照,系统可设定预警规则(如提前30天、15天、7天),自动向管理人员发送提醒通知;
-
对于存在年检或延续要求的证照,系统可记录历史延续记录,形成证照全生命周期档案。
异构版式的统一处理
-
企业收集的证照来源多样,版式差异较大。同一类证照可能因颁发年份、颁发地区、打印设备不同而在布局、字体、纸质上存在差异。传统基于模板的识别方法需要为每一种版式单独配置模板,维护成本高且难以覆盖所有情况。
-
基于大模型的抽取技术不依赖固定的版面位置规则,而是通过语义理解实现信息定位。实际测试表明,该技术对同一类证照的不同版式具有较好的适应性,新增版式无需额外配置模板,系统能够基于已学习的证照知识进行自主识别。
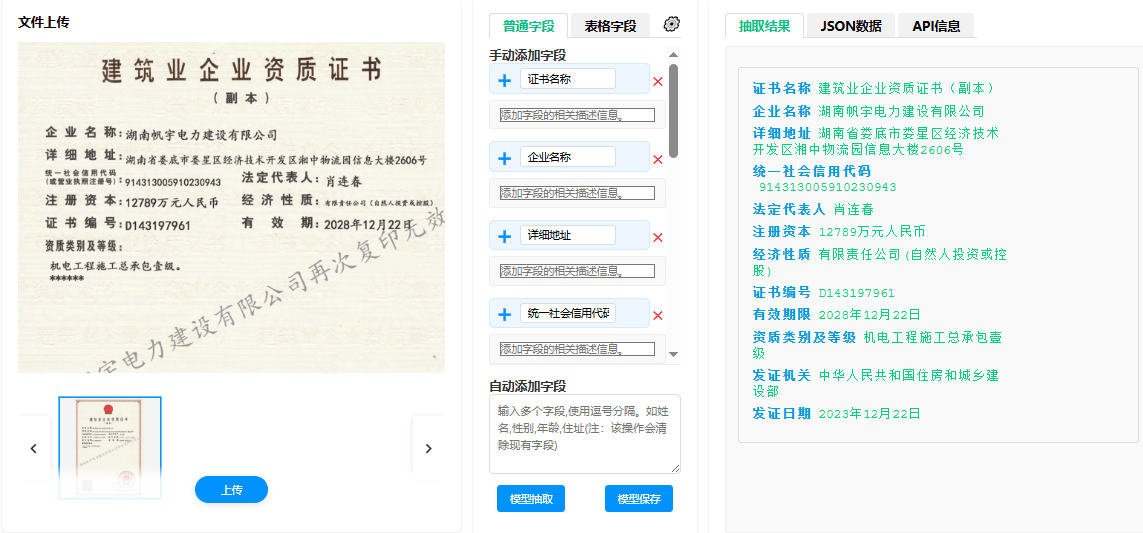
技术优势
-
语义理解驱动:相较于传统OCR加规则模板的方式,基于大模型的抽取技术能够理解字段的语义内涵,而非仅依赖位置或关键词匹配,在版式变化时具有更强的鲁棒性。
-
零样本/少样本泛化能力:得益于大模型强大的泛化特性,系统在仅输入少量样本甚至零样本的情况下,即可根据用户提供的证照样例或自然语言描述,快速推理出新的版式逻辑。
-
结构化输出:系统输出为结构化的JSON数据,可直接对接企业现有的ERP、OA、档案管理系统,减少数据转换环节。
-
持续学习能力:通过引入人工复核后的反馈数据,模型可进行增量微调,在实际使用过程中持续提升抽取准确率。
中科逸视将高精度OCR技术与领域微调的大模型相结合,构建了面向企业证照管理的智能文档抽取系统。该技术以语义理解为核心,实现了对多种版式证照文档的高精度信息抽取与结构化输出,有效支撑了证照入库、有效期监控、多证照关联核验等管理场景。技术的价值不仅体现在效率提升与差错降低,更在于将证照管理人员从重复性的信息录入工作中解放出来,转向更高价值的合规审核与风险管控工作。随着技术的持续迭代与场景应用的不断深入,智能文档处理技术有望在企业数字化管理领域发挥更为重要的作用。