专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2
在汽车制造厂的最终检测线旁,一沓沓纸质车辆合格证正等待着被录入系统。这些看似普通的文件,却是车辆出厂、销售、注册、上路的法定“身份证”,承载着车辆识别代号(VIN)、发动机号、排放标准、生产日期等数十项关键信息。传统的人工录入方式不仅效率低下、成本高昂,平均每份需要5至10分钟,且极易因疲劳或疏忽导致错误——一个数字的误录都可能引发后续销售、税务乃至合规环节的连锁问题。
中科逸视(北京)科技有限公司凭借其在人工智能领域的深厚积累,将前沿的计算机视觉技术与自然语言处理技术深度融合,推出车辆合格证识别系统。这套系统不再满足于简单的“看”到文字,而是致力于真正地“读懂”文档,为行业带来了革命性的效率与精度提升。

技术原理:双引擎驱动的深度理解
中科逸视车辆合格证识别技术的核心,是构建了一个“视觉感知(CV)→语义理解(NLP)→结构化输出与逻辑校验”的协同智能闭环。其完整流程可细化为以下五个环节:
1. 图像采集与预处理
首先,通过高拍仪、扫描仪或手机摄像头等设备采集合格证图像。图像质量直接影响后续识别精度,系统会自动执行一系列预处理操作:
2. 关键区域定位与检测
预处理后,系统需要对合格证进行“解剖”,精准定位关键信息的位置。合格证具有固定的版式结构,这一环节利用深度学习模型实现精准的区域检测:
3. 多模态字符识别
这是整个车辆合格证识别系统的核心环节。在定位到具体文本区域后,系统会根据文字类型采用不同的识别策略:
印刷体文字识别:主要采用CRNN(卷积循环神经网络)模型。该模型由三个核心模块协同工作:
4. 结构化解析与语义理解
识别出的原始文本是零散的,系统会利用自然语言处理(NLP) 技术进行“阅读理解”:
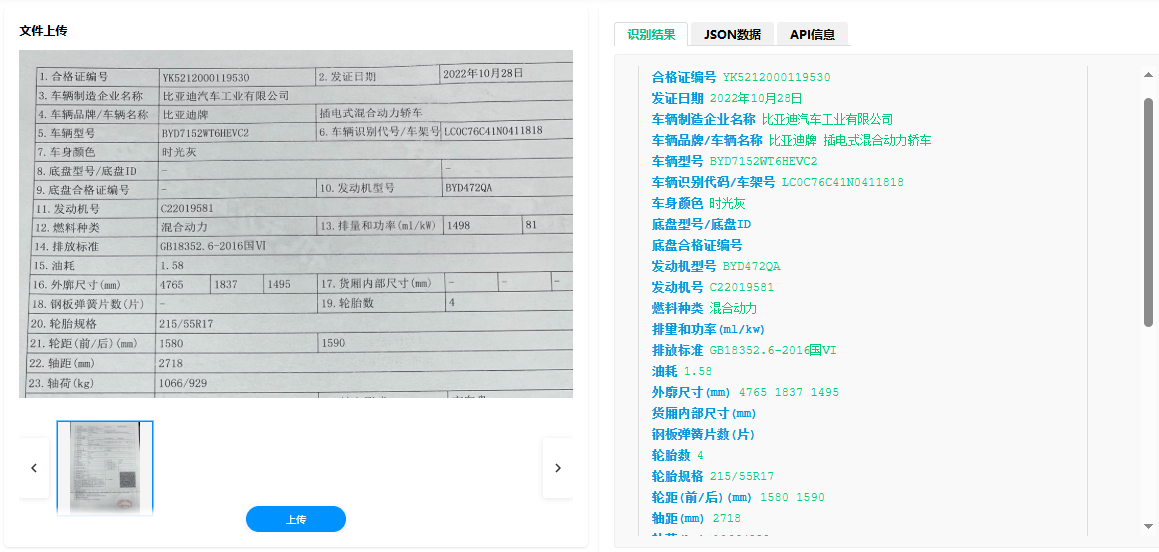
应用领域:赋能全产业链数字化升级
中科逸视的车辆合格证识别技术,已广泛应用于汽车行业的多个关键环节,成为推动业务数字化的重要引擎。
中科逸视的车辆合格证识别技术,不仅是OCR技术的简单应用,更是人工智能在垂直领域深度落地的典范。它通过计算机视觉与自然语言处理的深度融合,攻克了证件识别中的痛点难题,为汽车行业带来了前所未有的效率革命。